
어떠한 공부를 진행할 떄는 "왜"가 가장 중요하다
왜 이것을 하는가. 즉, 어떤 일을 진행할 때 결국 목적을 찾는 것이 가장 중요하기 때문이다.

현재 빅데이터에서는 이렇게 나아갈 수 있는 분야가 다양하다. 그리고 각자의 분야에서 필요한 능력은 상이하다.
그렇다면 현재 데이터 직무의 연력현황 및 수요는 어떠할까.

현재 데이터 직무 내에서는 데이터 분석가 / 과학자 < 데이터 개발자 의 인력이 필요한 상태이다.


하지만 향후 5년 내에는 데이터 분석가 / 과학자 > 데이터 개발자 의 비율로 데이터 직무 내에 인력이 부족하게 된다.
즉, 데이터 분석가 / 과학자가 앞으로 더 유망하다는 것을 현재로선 짐작 가능하다. 물론 빠르게 변화하는 세상이기에 '현재' 로서는 말이다.
그렇다면 데이터 과학(Data Science)의 과정은 어떻게 진행될까
데이터 과학은 크게 문제정의 > 데이터 수집 > 데이터 준비 > 데이터 분석 > 데이터 시각화 의 단계로 진행된다.
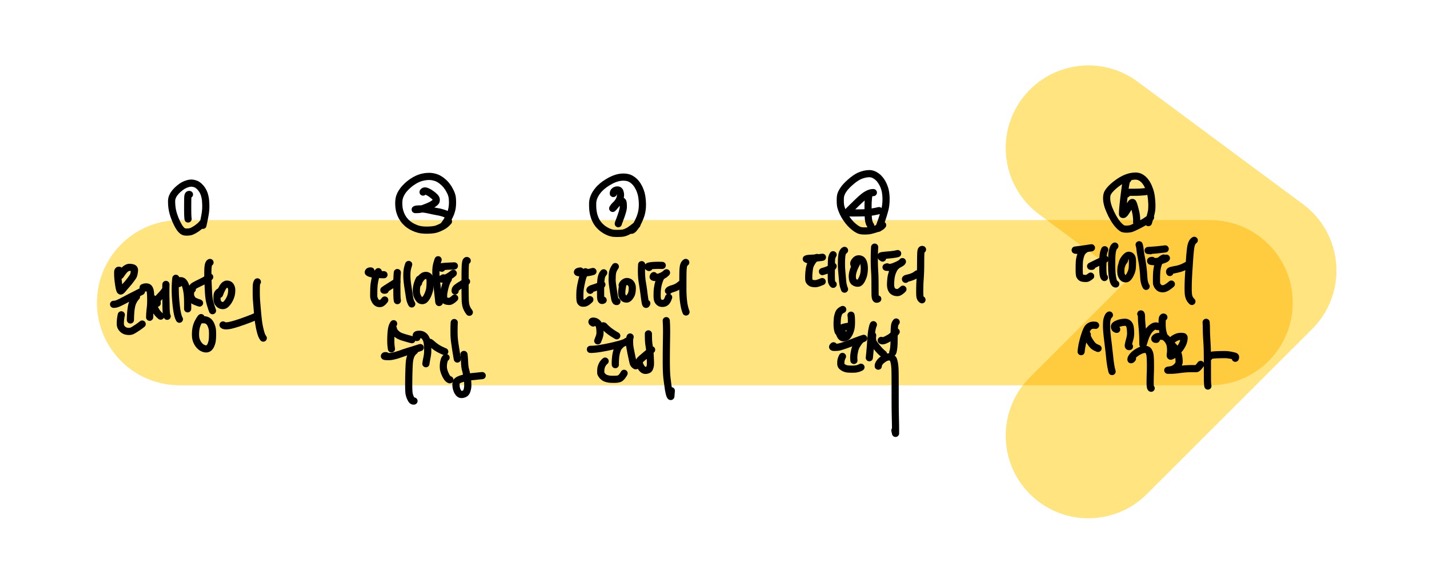

① 문제 정의 단계 (Problem Definition)
문제 정의 단계에서는 '데이터 덕분에 problem를 solve할 수 있는 문제(Problem) 고르기' 로 문제를 정의하면 좋다.
즉, 데이터가 없어서 해결할 수 없었던 문제를 선택하여, 해결할 수 있는 solution을 정의하면 좋다는 것이다.
② 데이터 수집 단계 (Data Acquisition)
데이터 수집 단계에서는 주의해야할 점 4가지가 있다.
Small Data / Meta Learning / Few-shot Learning / One-shot Learning 이다.
즉, Small Data로 야기된 Data bias를 조심해야한다.
③ 데이터 준비 단계 (Data Preparation)
데이터 준비 단계에서는 데이터를 탐색하고, 데이터를 전처리하는 과정을 가진다.
데이터를 탐색할때는, 데이터가 데이터 분석을 위해 적절히 준비되었는지 확인해야하고, 통계적 특징을 이해하며, 상관관계 / 트렌드 / 아웃라이어 등등.. 을 고려해야한다. 이 때, 상관관계와 아웃라이어 같은 경우는 상관 분석을 통해 알 수 있다.
또한, 데이터 전처리 단계에서는 무엇보다도 Null값 처리가 가장 중요하다(Imputation [: In statistics, imputation is the process of replacing missing data with substituted values.]) 만약 유의미한 데이터이지만, 100%중 3%만의 정보를 가지고 있고 나머지는 NULL값 상태라면, 지워야 할 것인가 아니면 사용해야할 것인가? 보통은 지우는 쪽을 택한다. 왜냐하면 나머지 97%의 데이터를 잘못된 데이터로 채워 분석을 한다면, 크나큰 오류를 범할 수 있기 때문이다. 그리고 데이터 전처리 단계에서는 불균형 데이터를 조작하는 것도 매우 중요하다. 남녀 성비 / 인종의 비율 등 우리는 어디서나 데이터의 Imbalaced를 발견 할 수 있다.
④ 데이터 분석 단계 (Data Analysis)
데이터 분석 단계에서는 데이터 분석 방식을 선택한다.
- 통계적 기법 (Statistical methods)
- 머신러닝 (machine learning)
- 딥러닝 (Deep Learning)
- 자기지도학습 (Self-supervised Learning)
에서 주로 택한다.
여기서 machine learning을 자세하게 본다면 Supervised Learning(지도학습)과 Unsupervised Learning(비지도학습)이 있다. Supervised Learning은 Input Data와 Label(Input Data에 대한 정답) 의 정보를 입력으로 받아 학습하며, Unsupervised Learning은 오직 Input Data만을 기반으로 군집을 찾는 학습을 진행한다. 쉽게 말해, 지도학습은 정답까지 알려주며 학습하는 것, 비지도학습은 정답없이 학습하는 것을 의미한다.
⑤ 데이터 시각화 (Data Visualization)
그리고 최종적으로 데이터 시각화 단계를 진행한다.
그래서, 인공지능의 최신 동향은 어떻게 될까.
바로 Transformer Network, BERT, GPT3이다.
이러한 발전은 2018년부터 본격적으로 시작되었다.
우선, Transformer Network를 알려면 Attention에 대해 알아야한다. Attention이 무엇인가? Attention 중 사진을 예로 든다면, 우리는 개라는 것을 인지할 때 개의 얼굴만을 볼 뿐, 개의 옷이나 개가 착용한 스카프 등을 주의깊게 보지 않는다. 문장을 예로 든다면, 우리는 '그녀가 푸른 사과를 먹는다.'라는 글을 볼때 '먹는다-사과를' 을 high attention으로 보고, '먹는다-푸른'은 low attention으로 본다. 그래서 짧게 얘기하자면, Transformer Network는 Attention기법을 사용한 모델이다.
다음, BERT는 사전 학습된 대용량의 Unlabeled 데이터를 이용하여 Language Model을 학습하고, 이를 통해 번역, 질의응답 등을 위한 신경망을 추가하는 전이 학습 방법이다.
마지막으로 GPT3은 최근 가장 핫한 주제로 in-context learning을 통해 few shot learning을 하는 것이다. 여기서 in-context learning이란 , zero-shot / one-shot / few-shot learning이 있는데, 대규모 언어 모델이 해당 작업에 대해 훈련이 되지 않았음에도 불구하고 몇가지 예만 본 후 작업을 수행하는 방법을 배우는 '상황 내 학습'이다. 그리고 few shot learning이란 , 말 그대로 'few' 적은 학습 데이터(samples)로도 평가 데이터를 올바르게 예측할 수 있는 learning이다.
그러나 이러한 GPT3에도 한계와 사회적 악영향은 존재한다. 첫째, 성능적 한계이다. 다음은 알고리즘적 한계, 마지막으로는 효율성이 떨어진다는 한계가 존재한다. 사회적 악영향으로는 잘못된 활용(가짜 에세이 등등..), 편향, 표현력, 에너지 사용등이 있다. 하지만 이러한 한계와 악영향에도 불구하고 각광받는 이유는 이러한 문제점을 해결하고 선한 영향력을 줄 수 있는 도구가 될 수 있어서이지 않을까.
'Data > Data visualization' 카테고리의 다른 글
| Self attention (0) | 2023.04.23 |
|---|